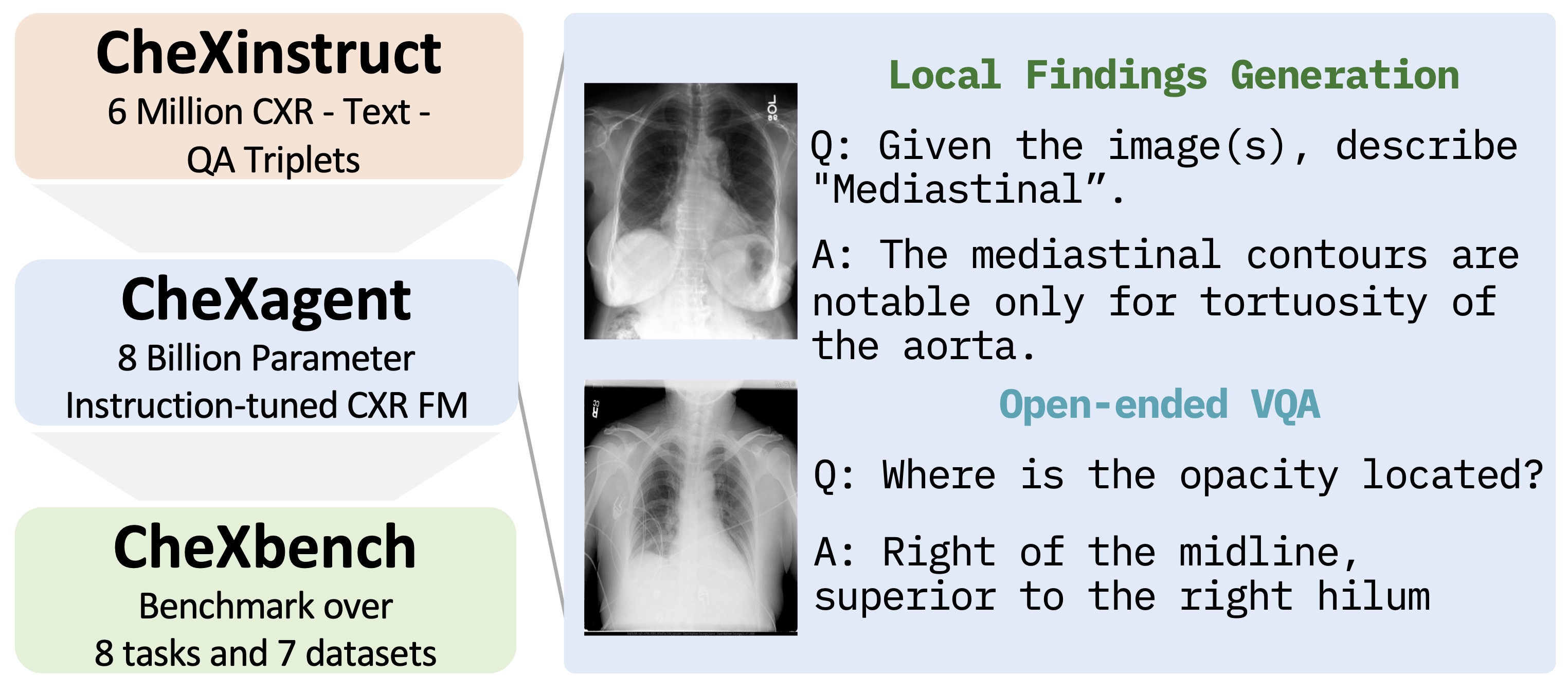
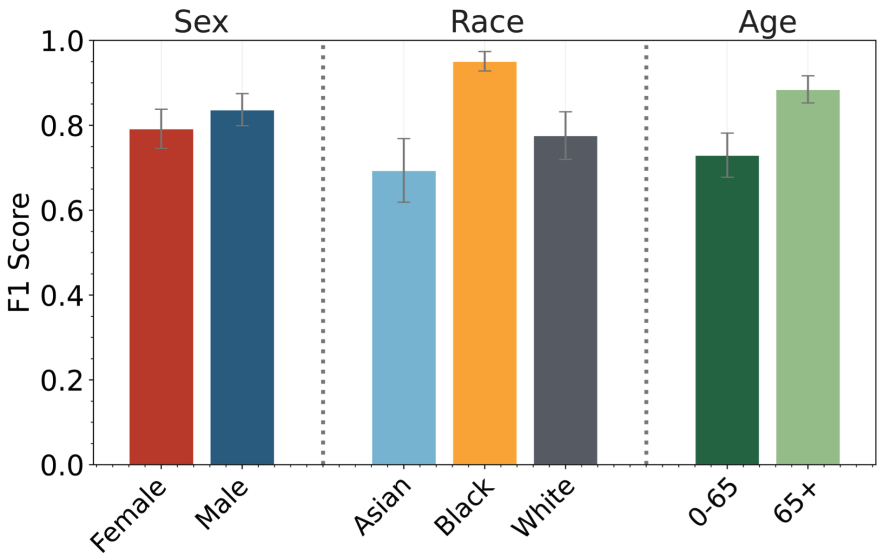Abstract
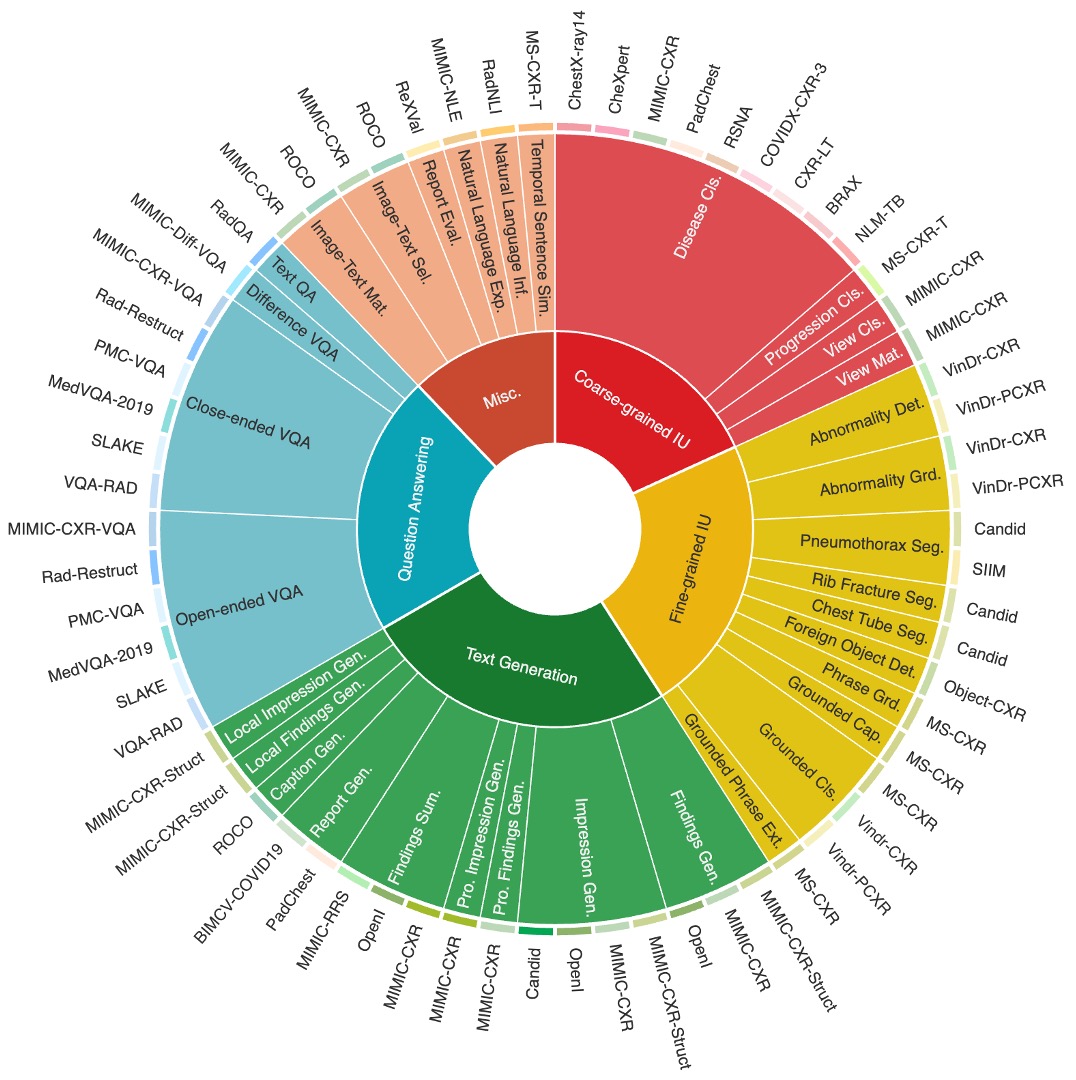
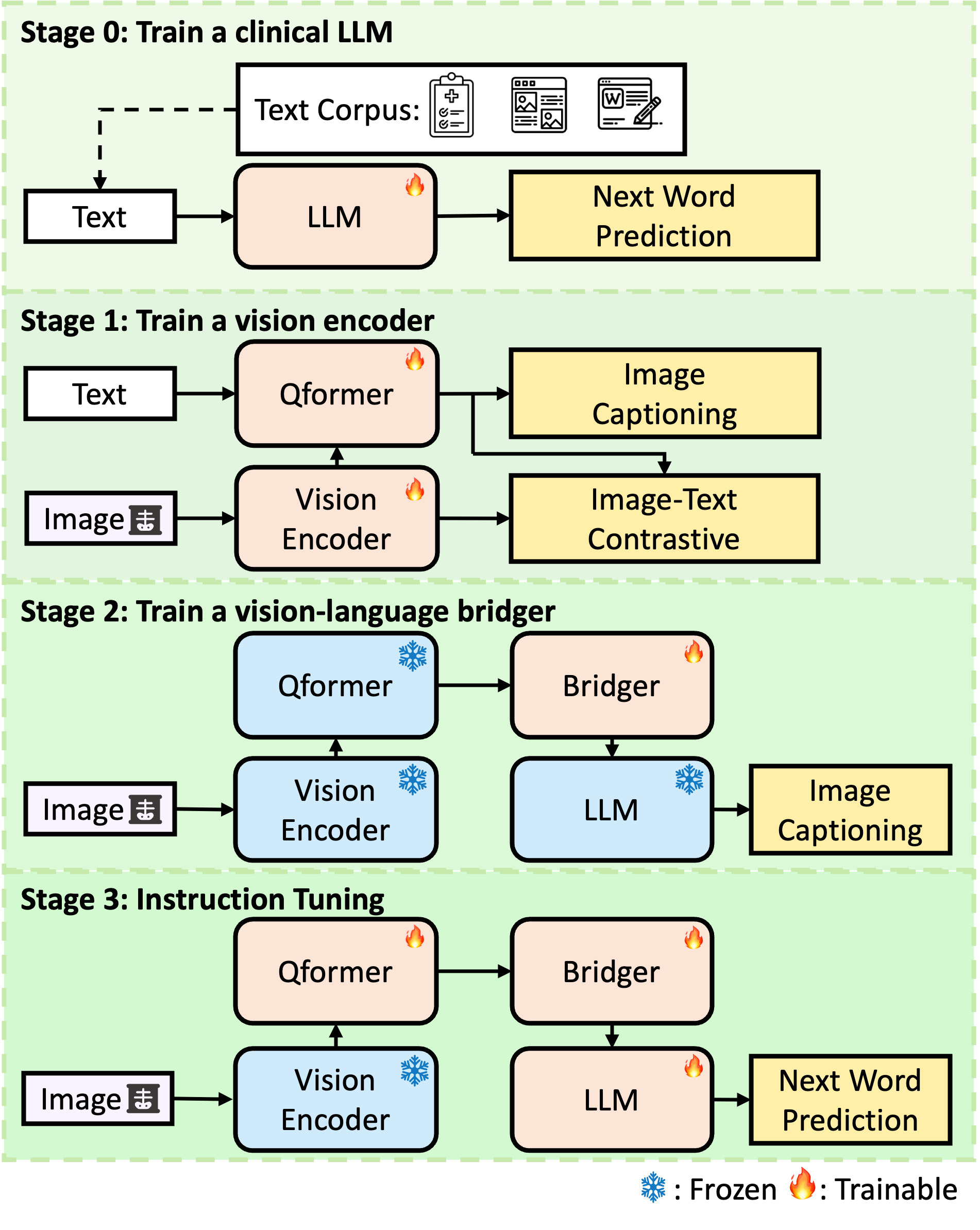
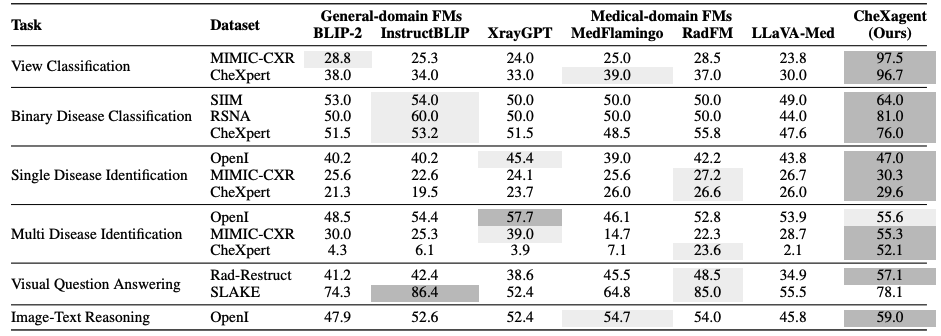
Chest X-rays (CXRs) are the most frequently performed imaging test in clinical practice. Recent advances in the development of vision-language foundation models (FMs) give rise to the possibility of performing automated CXR interpretation, which can assist physicians with clinical decision-making and improve patient outcomes. However, developing FMs that can accurately interpret CXRs is challenging due to the (1) limited availability of large-scale vision-language datasets in the medical image domain, (2) lack of vision and language encoders that can capture the complexities of medical data, and (3) absence of evaluation frameworks for benchmarking the abilities of FMs on CXR interpretation. In this work, we address these challenges by first introducing CheXinstruct - a large-scale instruction-tuning dataset curated from 28 publicly-available datasets. We then present CheXagent - an instruction-tuned FM capable of analyzing and summarizing CXRs. To build CheXagent, we design a clinical large language model (LLM) for parsing radiology reports, a vision encoder for representing CXR images, and a network to bridge the vision and language modalities. Finally, we introduce CheXbench - a novel benchmark designed to systematically evaluate FMs across 8 clinically-relevant CXR interpretation tasks. Extensive quantitative evaluations and qualitative reviews with five expert radiologists demonstrate that CheXagent outperforms previously-developed general- and medical-domain FMs on CheXbench tasks. Furthermore, in an effort to improve model transparency, we perform a fairness evaluation across factors of sex, race and age to highlight potential performance disparities. The figure below shows the overview of the proposed pipeline.